DeepExtract™: Advanced Document Understanding

DeepExtract™ represents our premium content extraction technology, using multiple specialized AI models to process documents.
This feature goes beyond basic text extraction, delivering deep understanding of complex document elements including tables, figures, mathematical formulas, code snippets, citations, and even scanned documents.
When you process a document with DeepExtract™, you receive a zip file containing all extracted content in multiple formats optimized for various use cases. This makes it perfect for implementing RAG (Retrieval-Augmented Generation) systems, knowledge management solutions, or complex data extraction pipelines.
The output package includes high-quality page images, essential for document retrieval tasks and compatible with document processing libraries such as ColPali and LitePali. To accommodate diverse implementation needs, we provide image content in both base64-embedded format and as separate reference files with corresponding paths.
The boundary detection system precisely identifies and maps the coordinates of every table and image within documents. Combined with state-of-the-art OCR technology, DeepExtract™ ensures exceptional accuracy in processing code blocks, mathematical expressions, and scanned documents.
A standout feature of DeepExtract™ is its deterministic JSON export capability. While our standard processing pipeline produces reliable probabilistic JSON output (ideal for web content extraction), many enterprise scenarios demand absolute precision. To meet this need, DeepExtract™ delivers two JSON variants: a streamlined version containing cleanly extracted text, and an advanced structured version that preserves the complete document hierarchy, enabling sophisticated element location and relationship mapping.
Originally developed for enterprise clients, DeepExtract™ is now available to both Pro and Enterprise users. Enterprise subscribers benefit from GPU-accelerated processing infrastructure, delivering superior speed and handling additional document formats. Pro users access the same powerful features through our efficient CPU-based processing pipeline, ensuring reliable performance for standard workloads.
This release marks just the beginning of our vision for DeepExtract™. We are committed to continuous innovation, working to establish DeepExtract™ as the industry standard for comprehensive document understanding and processing. Our roadmap includes expanding format support, enhancing processing capabilities, and introducing new features based on emerging technologies and user needs.
See more on the video:
The process
You can start from URL or file upload, as the standard processing.
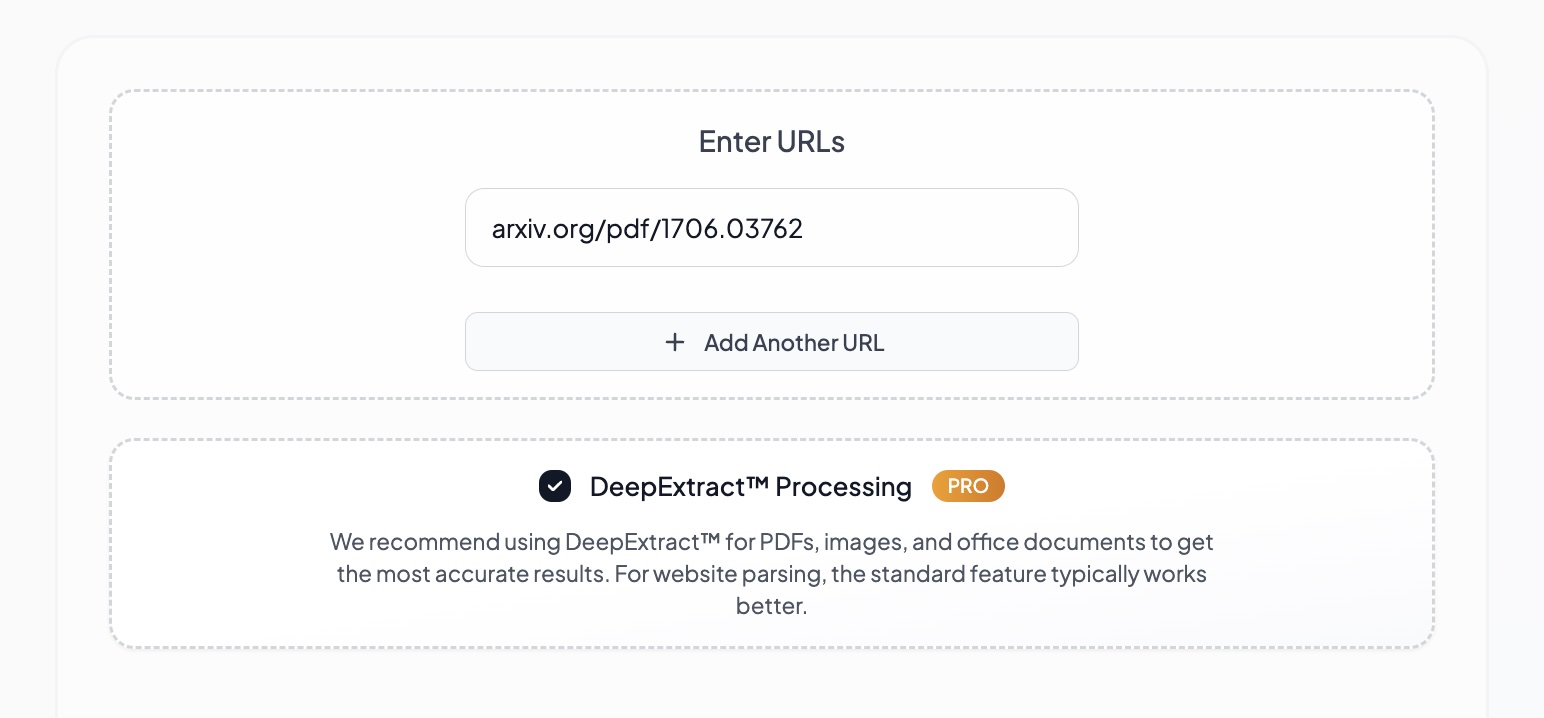
When processing is ready, you have the option to choose from different formats. Like deterministic JSON (full and simple), Markdown with embedded images or with links.
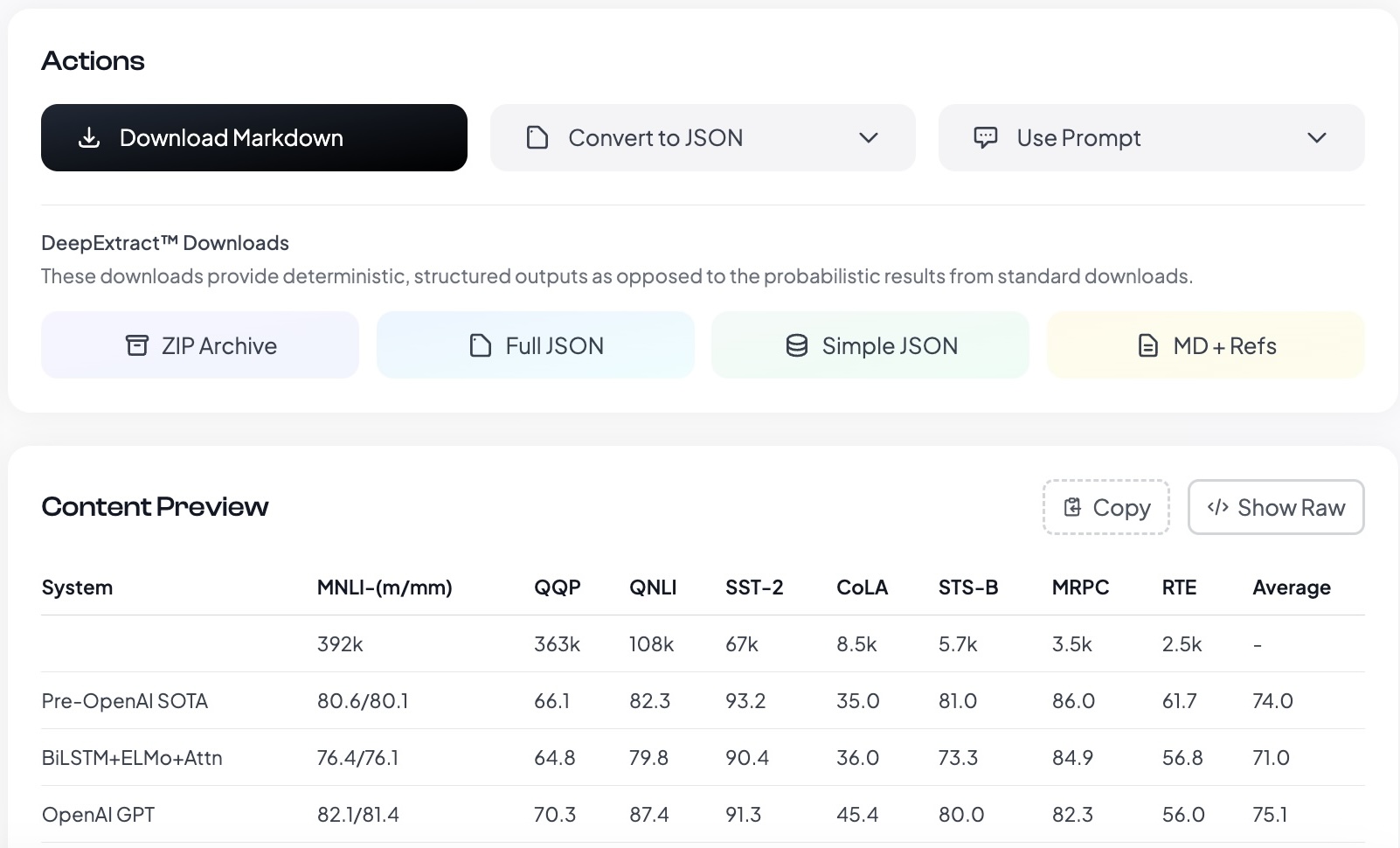
In the available ZIP file, you can find the extracted images, tables, page screenshots and all additional formats.